[이응수의 IT노트] 하둡(Hadoop)의 구성요소
남지숙
view : 826
[이응수의 IT노트] 하둡(Hadoop)의 구성요소
안녕하세요. 중앙HTA 이응수 강사입니다.
오늘 이응수의 IT노트에서는 하둡의 구성요소를 살펴보도록 하겠습니다.
하둡은 개인의 개발 PC에 테스트 목적으로 설치할 수도 있고, 네트워크상의 서로 다른 서버를 클러스터로 구성해서 설치할 수도 있습니다.
하둡의 설치가 완료되면, 빅데이터를 저장하고, 분석하기 위해서 하둡을 실행하게 되는데, "하둡을 실행한다"라는 의미는
여러 개의 데몬(deamon)을 실행하는 것을 말합니다.
이 데몬들은 각각 특별한 역할을 수행하는데 하나의 컴퓨터에 모든 데몬이 실행될 수 도 있고,
클러스터로 구성된 환경에서는 네트워크상의 서로 다른 서버에서 실행될 수 도 있습니다.
하둡의 데몬에는 NameNode, DataNode, SecondaryNameNode, JobTracker, TaskTracker 등이 있습니다.
하둡은 분산 저장과 분산 연산을 수행하기 위해서 master/slave 구조를 가지고 있습니다.
이런 분산저장시스템을 하둡 파일 시스템(Hadoop File System) 또는 HDFS라고 부릅니다.
하둡은 보통 master 역할을 수행하는 한 대의 NameNode와 slave 역할을 하는 여러 대의 DateNode로 구성됩니다.
HDFS에서 master 역할을 수행하는 NameNode는 slave인 DateNode에게 읽기/쓰기 작업을 지시하고, HDFS(하둡파일시스템)의 모든 정보를 관리합니다.
HDFS에서 파일을 저장하는 방식은 일반적인 파일저장방식과는 차이가 있습니다.
HDFS는 파일을 블록 단위로 나누어서 저장합니다. 하나의 블록 크기는 보통 128MB입니다.
크기가 큰 파일은 여러 개의 블록으로 나뉘고 각각의 블록은 여러 DateNode에 흩어져서 저장됩니다.
따라서, 어떤 DataNode가 어떤 블록을 저장하고 있는지 등의 정보를 관리할 필요가 있는데, NameNode가 그 정보를 가지고 있습니다.
HDFS에서 NameNode와 DataNode가 파일의 블록단위로 나누어서 저장하는 일반적인 모습은 아래와 같습니다.
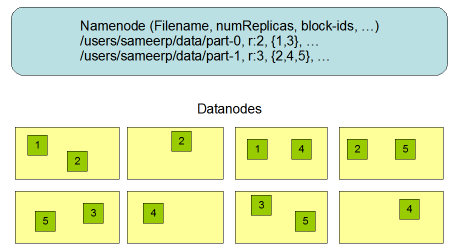
위의 그림처럼 NameNode는 파일의 메타데이터(디렉토리명, 파일명, 복제본 수, 블록의 위치정보)를 저장하고,
파일은 여러 개의 블록으로 나누어져서 여러 대의 DateNode에 블록단위로 저장됩니다.
그림에서 각 블록은 3개의 복사본을 가지게 됩니다. 이로 인해 하나의 DataNode에 장애가 생겨도 사용자는 장애없이 계속 파일을 읽을 수 있게 됩니다.
위의 그림처럼 하둡에서 NameNode는 복수 개 구성되지 않습니다.
그래서 하둡클러스터에서 NameNode는 단일장애지점이 됩니다. NameNode에 장애가 생기면 하둡 클러스터의 어떤 파일에도 접근할 수 없게 됩니다.
하둡의 slave노드에는 DataNode 데몬이 존재합니다.
DataNode는 사용자가 하둡파일시스템에 파일을 읽거나 쓸때, 이 파일들을 블록단위로 나누어서 저장하거나, 읽는 단순한 기능을 수행합니다.
클라이언트가 하둡파일시스템에서 파일을 읽거나 쓸때 NameNode는 그 파일의 블록이 어느 DataNode에 있는지 클라이언트에게 알려줍니다.
클라이언트는 블록을 읽기위해서 DataNode와 직접 통신해서 파일을 읽거나 씁니다.
DataNode는 주기적으로 heartbeat와 자신이 가지고 있는 블록정보를 NameNode로 보고합니다.
NameNode는 그 정보를 바탕으로 DataNode의 상태와 블록정보를 관리합니다.
SecondaryNameNode(SNN)는 NameNode의 백업서버가 아닙니다.
NameNode는 HDFS의 메타데이터를 메모리에서 처리합니다.
HDFS는 메모리에서 처리되는 HDFS의 메타데이터가 유실되지 않게 하기 위해서 editslog와 fsimage 파일을 사용합니다.
editslog는 HDFS의 모든 변경이력을 저장하고, fsimage는 메모리에 저장된 메타데이터를 파일시스템이지로 저장한 파일입니다.
NameNode가 초기화될 때 fsimage를 메모리로 로딩해서 새로운 메타데이터 파일시스템 이미지를 생성하고, 파일시스템 이미지에 editslog의 변경이력을 적용합니다.
이때 editslog의 파일 사이즈가 너무 크면 파일시스템 이미지 갱신에 많은 시간이 소요되게 되고, 이 시간동안 HDFS를 대상으로 읽기 쓰기 작업을 할 수 없게됩니다. SNN은 NameNode의 editslog와 fsimage를 다운받아서 fsimage를 갱신하는 역할을 대신 수행하는 데몬입니다.
SNN이 fsimage를 갱신하는 과정을 체크포인팅이라고 하고, 체크포인팅은 1시간 마다 주기적으로 일어납니다.
하둡은 데이터의 저장과 관련해서 master/slave구조의 NameNode, DataNode로 구성되어 있는 것과 마찬가지로
데이터의 연산처리과 관련된 데몬도 master/slave 구조를 가지고 있습니다.
JobTracker 데몬은 master 역할을 수행하고, TaskTracker는 slave 역할을 수행합니다.
JobTracker는 master로서 사용자가 제출한 MapReduce 애플리케이션의 전체 실행을 감독합니다.
사용자가 MapReduce 애플리케이션을 하둡에 제출하면 JobTracker는 여러 가지 실행계획을 결정하고, 클러스터의 여러 노드에 task를 할당합니다.
여기서 Task는 사용자가 제출한 MapReduce 애플리케이션을 HDFS에서 병렬처리가 가능하도록 분할한 처리단위입니다.
JobTracker는 실행되는 모든 Task를 모니터링하고, Task가 실패하면 자동으로 실패한 Task를 실행합니다.
하둡 클러스터에서 하나의 JobTracker 데몬만 존재합니다. JobTracker와 TaskTracker의 관계는 아래 그림과 같습니다.
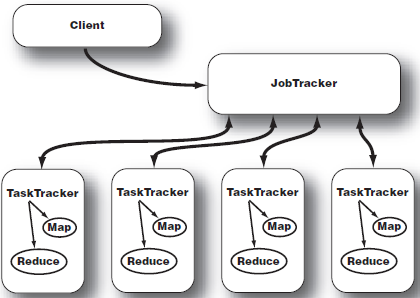
각 TaskTracker는 각 salve 노드에 할당된 작업의 실행을 담당합니다.
각각의 TaskTracker는 JobTracker가 할당한 개별작업을 실행합니다.
각 slave노드에는 TaskTracker가 하나만 존재하지만, 여러 개의 JVM을 생성해서 다수의 map작업과 reduce작업을 병렬처리할 수 있습니다.
TaskTracker는 JobTraker에게 주기적으로 heartbeat를 전송합니다.
JobTracker는 TaskTracker로부터 정해진 주기내에 heartbeat가 도착하지 않으면 해당 TaskTracker에 문제가 발생했다고 간주하고,
해당 작업을 하둡 클러스터 내에 위치한 다른 노드에 할당합니다.
지금까지 하둡의 구성요소들과 하둡클러스터의 구조를 간단히 살펴보았습니다.
NameNode와 DataNode 데몬은 HDFS에 데이터를 읽고 쓰는 작업과 관련된 데몬 프로그램이고,
JobTracker와 TaskTracker는 하둡 클러스터에서 MapReduce 애플리케이션의 병렬처리를 지원하는 데몬 프로그램이라고 할 수 있습니다.
이상 하둡(Hadoop)의 구성요소를 마치도록 하겠습니다.
다음에는 MapReduce 프레임워크에 대해서 알아보겠습니다.
어느덧 2017년 9월도 얼마 남지 않았네요.
마무리 잘하시고 즐거운 추석 연휴 보내시기 바랍니다.
감사합니다.
<저작권자(c)중앙에이치티에이(주). 무단전재-재배포금지>





{kind=link}
{kind=link}