[이응수강사의 IT노트] 하둡 (Hadoop) 개발환경 설치 방법
임재훈
view : 982
[이응수강사의 IT노트] 하둡 (Hadoop) 개발환경 설치 방법
안녕하세요. 중앙HTA 이응수 강사입니다.
이번 이응수의 IT노트에서는 하둡(Hadoop) 분산환경의 데이터 처리 방식과 하둡(Hadoop) 개발환경 설치과정을 설명하도록 하겠습니다.
먼저 간단하게 하둡(Hadoop)에 대해서 알아보도록 하겠습니다.
하둡(Hadoop)은 대용량 데이터를 처리하는 분산 응용 프로그램을 작성하고 실행시키기 위한 오프소스 프레임워크입니다.
하둡(Hadoop)의 장점으로는 다른 분산 컴퓨팅 시스템에 비해서 접근성, 견고성, 확장가능성이 매우 뛰어납니다.
하둡(Hadoop)은 윈도우 PC와 같은 범용 컴퓨터들로 큰 규모의 클러스터 환경을 쉽게 구성할 수 있고, 하드웨어의 빈번한 고장을 가정하고 설계되었기 때문에 하드웨어 고장 발생시 적절한 대응을 할 수 있습니다.
하둡(Hadoop)은 단순히 컴퓨터를 추가함으로써 클러스터 규모를 선형적으로 확장할 수 있고, 분산환경에서 실행되는 병렬코드를 간단하고 빠르게 작성할 수 있습니다.
하둡(Hadoop)의 이런 특징은 초보자도 빠르고 저렴한 비용으로 하둡 클러스터를 쉽게 구성하고, 분산 컴퓨팅 환경에서 실행되는 프로그램을 작성하고 실행해볼 수 있게 합니다.
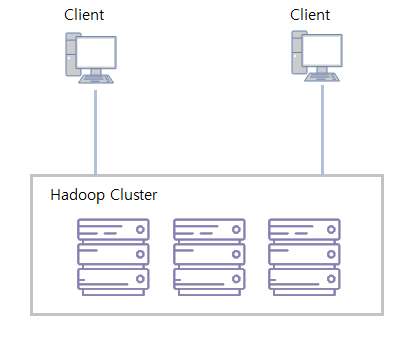
일반 사용자가 하둡 클러스터와 어떤 식으로 상호작용하는지는 아래의 그림으로 나타낼 수 있습니다.
하둡 클러스터는 네크워크로 연결된 범용 컴퓨터들의 집합체입니다. 데이터의 저장과 처리는 모두 하둡 클러스터 내에서 이루어집니다.
사용자들은 개인 컴퓨터를 통해서 필요로 하는 연산 작업을 하둡 클러스터에 요청하기만 하면 됩니다.
다음으로 하둡 클러스터 내에서 어떻게 데이터를 처리하는지를 설명하겠습니다.
하둡(Hadoop)의 데이터 처리 모델은 MapReduce 프레임워크입니다.
MapReduce 프레임워크를 사용해서 데이터를 처리하는 응용프로그램을 작성하면 확장성, 병렬성, 내고장성과 같은 일은 하둡(Hadoop)이 모두 알아서 처리해 주기 때문에 사용자는 데이터를 처리하는 로직의 구현에만 집중하면 됩니다.
MapReduce 프레임워크는 크게 매핑(mapping)과 리듀싱(reducing)의 두 단계로 나누어서 처리됩니다.
각각의 단계는 mapper와 reducer라는 데이터 처리 메소드로 정의되어 있습니다. mapper는 입력데이터를 필터링하고 reducer가 처리할 수 있는 형태로 데이터를 변형합니다. reducer는 mapper로부터 데이터를 받아서 데이터를 통합하는 작업을 수행합니다.
매핑과 리듀싱은 데이터를 처리할 때 많은 프로그램에서 공통적으로 발견되는 특징을 모델링한 것입니다.
그리고 분산 컴퓨터 환경에서는 여러 대의 컴퓨터를 사용해서 입력데이터를 필터링하고 변형하는 매핑 단계를 수행한 후에 그 결과값을 reducer함수에게 전달하는 과정에서 특별한 처리가 필요합니다.
리듀싱 단계에서 각 컴퓨터들이 독립적으로 작업을 처리하기 위해서는 적절한 크기로 데이터가 분할되어 각 컴퓨터로 전달되어야 합니다.
이 과정을 셔플링(suffling)이라고 합니다. 셔플링 단계에서는 mapper의 출력 데이터를 파티셔닝(partitioning)과 정렬(sorting)을 활용해서 reducer함수의 입력 데이터로 전달합니다.
셔플링과 파티셔닝은 모든 MapReduce 프로그램에서 공통적으로 사용되는 일반적인 단계이기 때문에 하둡의 MapReduce 프레임워크에서는 대부분의 상황에서 사용할 수 있는 기본 기능을 제공하고 있습니다.
MapReduce는 위에서 설명한 매핑, 리듀싱, 파티셔닝, 셔플링 단계가 적절하게 동작하게 하기 위해서 특별한 데이터 구조를 사용합니다.
MapReduce는 키와 값의 한 쌍으로 구성된 리스트를 데이터의 기본 단위로 사용합니다.
MapReduce 프레임워크의 매핑단계와 리듀싱단계의 입력과 출력데이터의 형식은 아래와 같습니다.
입력 | 출력 | |
map | <k1, v1> | list(k2, v2) |
reduce | <k2, list(v2)> | list(k3, v3) |
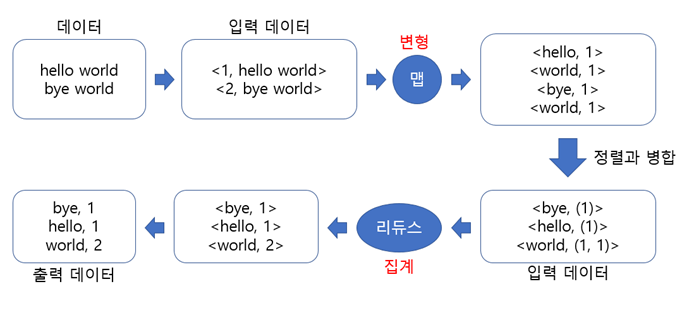
그럼, 간단한 단어세기 예제를 통해서 하둡의 MapReduce 프레임워크의 데이터 흐름을 살펴보도록 하겠습니다.
이 예제에서 데이터는 텍스트를 포함하고 있는 파일입니다. 각 단계의 입력데이터는 반드시 키와 값으로 구성되어 있어야 합니다.
mapper에 있는 map함수는 키/값(<k1, v1>)으로 이루어진 입력데이터를 전달받아서 하나씩 처리합니다.
보통 k1은 파일의 행번호이고, v1은 각 행의 레코드입니다.
map함수는 각각의 <k1, v1>을 <k2, v2>형태로 변환합니다. 이 예제에서는 레코드를 공백단위로 잘라서 <word, count>로 변환합니다.
셔플링 단계에서는 mapper의 처리결과를 k2의 값이 같은 경우, 새로운 <k2, list(v2)>의 형태로 가공해서 reducer에 전달합니다.
이 예제에서는 world 단어가 2번 나오는 경우 <world, list(1, 1)>과 같은 형대로 구성됩니다.
reducer에 있는 reduce함수는 <k2, list(v2)>의 형태로 전달받은 입력데이터를 집계해서 <k3, v3>의 형태로 출력하는데,
이 예제에서는 <world, list(1, 1)>을 <world, 3>의 형태로 집계해서 파일에 기록합니다.
단어세기 예제에서 살펴본 것처럼 사용자는 데이터 처리에 적합한 형태로 입력데이터를 변형하는 맵함수를 정의하면 MapReduce 프레임워크는 셔플링과 파티셔닝을 사용해서 맵함수의 출력데이터를 정렬하고 병합해서 리듀스 함수로 전달합니다.
리듀스 함수에서는 key별로 병합된 입력데이터를 전달받아서 실질적인 데이터 분석을 수행하는 작업을 구현하면 됩니다.
이번에는 하둡 개발환경의 설치과정을 설명하도록 하겠습니다.
하둡은 독립실행 모드, 가상분산 모드, 완전분산모드 3가지의 실행모드를 가지고 있습니다.
독립실행모드는 하둡의 기본 모드입니다. 하둡 환경설정파일에 아무런 설정하지 않고 실행하면 로컬 장비에서만 실행되는 독립실행 모드가 됩니다.
하둡에서 제공하는 여러 데몬들이 실행되지 않기 때문에 분산환경을 고려한 테스트가 불가능합니다.
가상분산 모드는 한 대의 컴퓨터로 클러스터를 구성하는 것입니다. 하둡의 모든 데몬이 한 대의 컴퓨터에서 실행됩니다.
일반적으로 하둡을 처음으로 공부하는 사람들이 MapReduce 프로그램을 작성하고 테스트해보기 위해서 가상분산 모드로 하둡 개발환경을 구성합니다.
완전분산 모드는 여러 대의 장비로 하둡 클러스터를 구성하는 것입니다. 하둡으로 실제 서비스를 하게 될 경우 완전분산 모드로 구성하게 됩니다.
이번 과정에서 가상분산 모드로 하둡환경을 구성하는 경우에 대한 설명을 하도록 하겠습니다.
하둡은 리눅스 및 다양한 유닉스 계열 운영체제에 설치할 수 있습니다.
윈도우를 사용하는 경우 오라클 VirtualBox를 설치해서 리눅스 가상머신 환경을 구성하도록 합니다.
이번 과정에서는 VirtualBox에 우분투 16.04.3을 설치한 후 하둡을 설치하는 과정을 설명하도록 하겠습니다.
VirtualBox의 설치과정과 우분투 설치과정은 아래의 url을 참고하시기 바랍니다.
VirtualBox 설치방법 : https://extrememanual.net/7184
VirtualBox에 우분투 설치방법 : https://extrememanual.net/7223
우분투를 포함한 데비안 계열 리눅스는 apt-get(Advanced Packing Tool)이라는 패키지 관리 도구를 제공합니다.
apt-get를 활용해서 개발과 관련된 패키지를 설치할 수 있다.
하둡을 설치하기 위해서는 먼저 자바가 설치되어 있어야 합니다.
# apt-get으로 패키지 인덱스 정보를 업데이트 합니다.

# openjdk를 설치합니다.
![]()
# 설치된 자바 버전을 확인합니다.

# JAVA_HOME을 .bashrc 파일에 등록하도록 하겠습니다.
# .bashrc파일의 끝에 JAVA_HOME 환경변수를 추가합니다.
![]()
![]()
# javac에 대한 절대경로를 설치된 openjdk의 javac로 설정합니다.

다음으로 하둡 사용자 계정을 생성하도록 합니다.
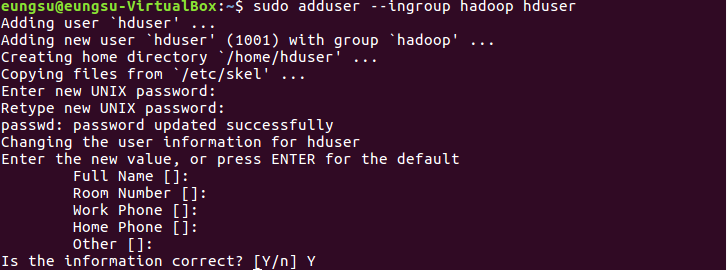
# 하둡 사용자 계정을 위한 그룹(hadoop) 생성하겠습니다.

# 하둡 사용자(hduser)를 생성하고 hadoop 그룹에 추가합니다.
# 생성된 하둡계정이 sudo 명령어를 실행할 수 있도록 합니다.


다음은 SSH패키지 설치 및 관련 설정을 하겠습니다.
하둡은 클러스터를 구축할 때 master노드와 slave노드로 구성하게 됩니다.
master노드는 클러스터에 위치한 slave노드에 접근해서 하둡의 데몬을 실행시켜야 하는데 이러한 접근을 위해서 SSH를 이용합니다.
SSH는 표준 공개키 암호화를 이용해서 한 쌍의 키를 생성합니다. 이 키는 사용자를 확인하는데 사용됩니다.
# SSH 패키지를 설치합니다.
![]()
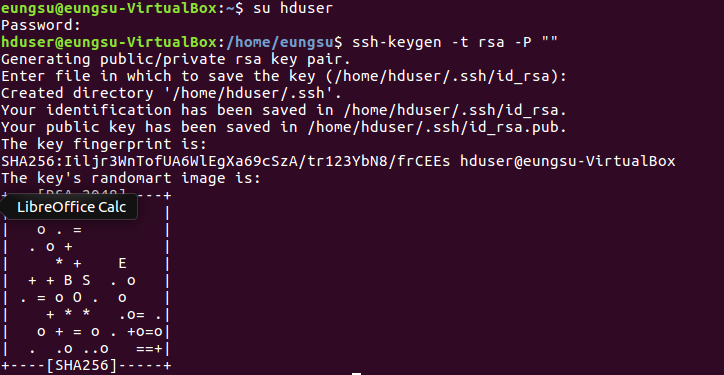
# 암호를 입력하지 않아도 로그인할 수 있도록 다음과 같이 빈 암호를 가진 SSH키를 생성합니다.
# 생성된 id_rsa.pub 파일을 authorized_keys 파일에 추가합니다.
![]()
# SSH를 이용해서 접속할 수 있는지 확인해봅니다.

자바와 SSH설치가 완료되었으면 하둡을 설치하도록 하겠습니다. 본 과정에서는 hadoop-1.2버전을 설치해보도록 하겠습니다.
# wget을 이용해서 하둡을 다운받습니다.
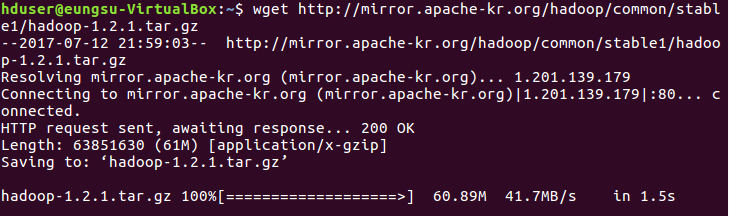
# 다운받은 하둡파일을 현재 디렉토리에 압축 해제합니다.
![]()
# /usr/local 디렉토리에 hadoop 디렉토리를 생성합니다.
![]()
# 위에서 압축 해제한 하둡파일을 /usr/local/hadoop 디렉토리로 이동시키고, 디렉토리에 대한 접근권한을 변경합니다.

하둡 파일 설치가 완료되었으면 가상분산모드로 동작하도록 하둡환경파일에 설정정보를 추가해보겠습니다.
하둡 환경설정파일은 하둡설치경로/conf 폴더에 있습니다.
하둡환경 설정 파일은 hadoop-env.sh, core-site.xml, hdfs-site.xml, mapred-site.xml 파일을 수정해야 합니다.
hadoop-env.sh는 하둡을 실행하는 셜스크립트에서 필요한 환경변수를 설정합니다. 이 파일에는 JDK 경로등을 설정합니다.
core-site.xml은 hdfs와 맵리듀스에서 공통적을 사용할 환경정보를 설정합니다.
hdfs-site.xml은 hdfs에서 사용할 환경 정보를 설정합니다.
mapred-site.xml은 맵리듀스에서 사용할 환경 정보를 설정합니다.
# hadoop-env.sh에 JDK 설치경로를 추가합니다.

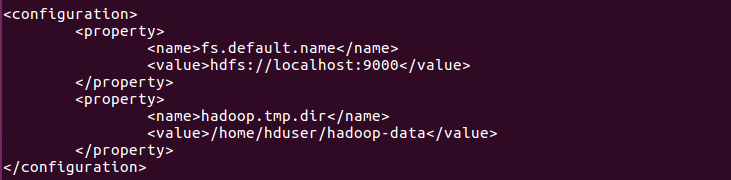
# core-site.xml에 네임노드 주소와 하둡에서 발생하는 임시 데이터를 저장하는 디렉토리를 설정합니다.
# 디렉토리는 미리 생성되어 있어야 합니다.
![]()
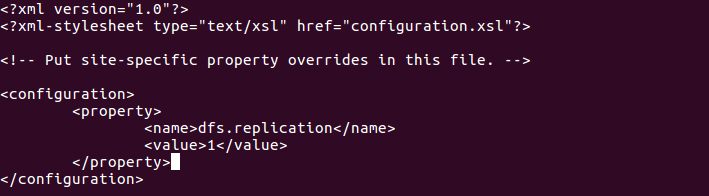
# hdfs-site.xml에 복제본 갯수를 설정합니다.
![]()
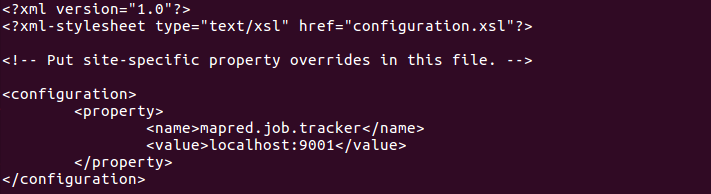
# mapred-site.xml에 잡트래커 데몬의 주소를 설정합니다.
![]()
하둡 환경설정파일의 수정이 완료되면 하둡 네임노드를 초기화합니다.
# 하둡 네임노드를 포맷합니다.
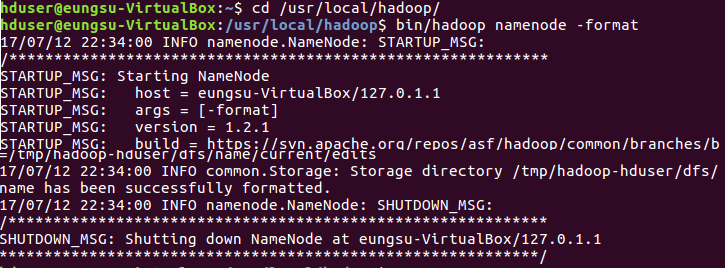
하둡 데몬을 실행시키고, 하둡 데몬이 정상적으로 실행되었는지 확인하면 하둡 설치가 완료됩니다.
# 하둡 데몬을 실행합니다.
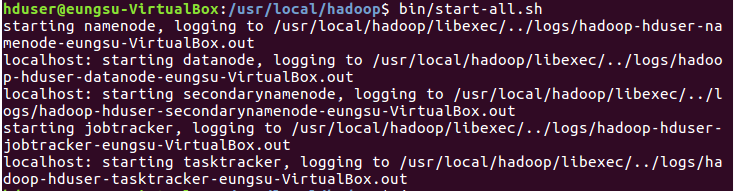
# 모든 하둡데몬이 정상적으로 실행되었는지 확인합니다.

네임노드, 보조네임노드, 잡트래커, 데이터노드, 태스크트래커가 정상적으로 실행중인 것을 확인할 수 있습니다.
이것으로 하둡의 가상분산모드 설치가 완료되었습니다.
# 모든 하둡 데몬의 종료는 stop-all.sh를 실행하면 됩니다.
설치과정에서 등장하는 하둡의 구성요소들은 다음 글에서 자세히 설명하도록 하겠습니다.
그럼 더운 날씨에 모두들 건강 조심하세요!
<저작권자(c)중앙에이치티에이(주). 무단전재-재배포금지>





{kind=link}
{kind=link}